
TLDR; In this article, we will show how to parse PDF and webpage into Markdown format – which can preserve document structure for better LLM understanding.
Document Parsing
In RAG, it is very common to upload our documents (i.e. PDF, spreadsheet, docs, or website) to the vector database so we can augment the LLM knowledge from it. One integral step is parsing the document itself, which the result must represent the document in the best way.
The easiest way to do that, is just read the file and get the contents. However, it is very possible to make the content losing it structures. Gratefully, we can mitigate this by parsing the document into structured format – Markdown. To the best of my experience, most LLMs are work best with Markdown format – especially OpenAI’s family.
To parse PDF file into Markdown, we can leverage the extended version of PyMuPDF library, called PyMuPDF4LLM.
This library is designed specifically to produce the best output that works well with LLM. Without further ado, let’s see how we can use it to parse PDF document.
First, we need to install the library itself.
pip install pymupdf4llm
We will use these sample PDFs from https://www.princexml.com/samples/. Optionally, you may also use your own PDF file.
Fortunately, it is very easy to convert it into markdown using pymupdf4llm. In this article we will only work with one of them. You can find the rest implementation on GitHub repo.
import pymupdf4llm
# these files are downloaded from link above
filepath = {
"invoice1": "assets/invoice.pdf",
"invoice2": "assets/invoice2.pdf",
"brochure": "assets/brochure.pdf",
"newsletter": "assets/newsletter.pdf",
"textbook": "assets/textbook.pdf",
}
newsletter = pymupdf4llm.to_markdown(filepath["newsletter"], show_progress=False)
print(newsletter)
Here is the parsed document output:
# DrylabNews
#### for investors & friends · May 2017
Welcome to our first newsletter of 2017! It's
been a while since the last one, and a lot has
happened. We promise to keep them coming
every two months hereafter, and permit
ourselves to make this one rather long. The
big news is the beginnings of our launch in
the American market, but there are also
interesting updates on sales, development,
mentors and (of course) the investment
round that closed in January.
**New capital: The investment round was**
successful. We raised 2.13 MNOK to match
the 2.05 MNOK loan from Innovation
Norway. Including the development
agreement with Filmlance International, the
total new capital is 5 MNOK, partly tied to
the successful completion of milestones. All
formalities associated with this process are
now finalized.
**New owners: We would especially like to**
warmly welcome our new owners to the
Drylab family: Unni Jacobsen, Torstein Jahr,
Suzanne Bolstad, Eivind Bergene, Turid Brun,
Vigdis Trondsen, Lea Blindheim, Kristine
## 34
### meetingsmeetings
NY · SFNY · SF
LA · LLA · LVV
Academy of Motion Picture Arts and Sciences · Alesha & Jamie Metzger · Amazon
AWS · Apple · Caitlin Burns, PGA · Carlos Melcer · Chimney L.A. · Dado Valentic ·
Dave Stump · DIT WIT · ERA NYC · Facebook · Fancy Film · FilmLight · Geo Labelle ·
Google · IBM · Innovation Norway (NYC) · Innovation Norway (SF) · International
Cinematographers Guild · NBC · Local 871 · Netflix · Pomfort · Radiant Images ·
Screening Room · Signiant · Moods of Norway · Tapad · Team Downey
-----
Holmsen, Torstein Hansen, and Jostein
Aanensen. We look forward to working with
you!
**Sales: Return customer rate is now 80%,**
proving value and willingness to pay. Film
Factory Montreal is our first customer in
Canada. Lumiere Numeriques have started
using us in France. We also have new
customers in Norway, and high-profile users
such as Gareth Unwin, producer of Oscar[winning The King's Speech. Revenue for the](http://www.imdb.com/title/tt1504320/)
first four months is 200 kNOK, compared to
339 kNOK for all of 2016. We are working
on a partnership to safeguard sales in
Norway while beginning to focus more on
the US.
... (We trimmed the output)
From the result above, we can see there is ----- token denoting different pages.
Although, the parsed result is not perfect, the output’s structure is good enough as it also maintain separation of each document parts.
As comparison, we shall look into Langchain PyPDFLoader implementation.
💡 Make sure you already install langchain on your machine.
from langchain_community.document_loaders import PyPDFLoader
lc_newsletter = "\n==================\n".join(doc.page_content for doc in list(PyPDFLoader(filepath["newsletter"]).lazy_load()))
print(lc_newsletter)
💡 Note that langchain document loader’s implementation always return list of langchain
Documentobject – each page represented by an object. Therefore we join them with separator token==================to denote different pages.
Here is the result of Langchain PyPDFLoader:
Drylab Newsfor in vestors & friends · Ma y 2017
Welcome to our first newsletter of 2017! It's
been a while since the last one, and a lot has
happened. W e promise to k eep them coming
every two months hereafter , and permit
ourselv es to mak e this one r ather long. The
big news is the beginnings of our launch in
the American mark et, but there are also
interesting updates on sales, de velopment,
mentors and ( of course ) the in vestment
round that closed in January .
New c apital: The in vestment round was
successful. W e raised 2.13 MNOK to matchthe 2.05 MNOK loan from Inno vation
Norwa y. Including the de velopment
agreement with Filmlance International, the
total new capital is 5 MNOK, partly tied to
the successful completion of milestones. All
formalities associated with this process are
now finalized.
New o wners: We would especially lik e to
warmly welcome our new owners to the
Drylab family: Unni Jacobsen, T orstein Jahr ,
Suzanne Bolstad, Eivind Bergene, T urid Brun,
Vigdis T rondsen, L ea Blindheim, Kristine
34meetingsmeetings
NY · SFNY · SF
LA · LLA · L VVAcadem yofMotion Picture Arts and Sciences ·Alesha &Jamie Metzger ·Amazon
AWS ·Apple ·Caitlin Burns, PGA ·Carlos Melcer ·Chimne yL.A.·Dado Valentic ·
DaveStump ·DIT WIT ·ERA NYC·Facebook ·Fancy Film ·FilmLight ·Geo Labelle ·
Google ·IBM ·Inno vation Norwa y(NY C)·Inno vation Norwa y(SF) ·International
Cinematogr aphers Guild ·NBC ·Local 871 ·Netflix ·Pomfort ·Radiant Images ·
Screening Room · Signiant · Moods of Norwa y· Tapad · Team Downe y
==================
Holmsen, T orstein Hansen, and Jostein
Aanensen. W e look forward to working with
you!
Sales: Return customer r ate is now 80%,
pro ving value and willingness to pa y. Film
Factory Montreal is our first customer in
Canada. Lumiere Numeriques ha ve started
using us in F rance. W e also ha ve new
customers in Norwa y, and high-profile users
such as Gareth Un win, producer of Oscar-
winning The King's Speech . Re venue for the
first four months is 200 kNOK, compared to
339 kNOK for all of 2016. W e are working
on a partnership to safeguard sales in
Norwa y while beginning to focus more on
the US.
Pay attention the output documents structure are not preserved, making its hard to identify which part originally belongs to. In addition, if we take a closer look, some captured words are strangely separated by random whitespace.
Although the LLM may still can understand it, I believe giving better input representation will produce better output as well. Therefore, parsing into markdown format is a good choice to enhance LLM understanding of our document.
Now we already know how to parse PDF into markdown format. What if I am telling you that you can do the same to webpages?
Let’s look how to do it.
Webpage
To parse webpage into Markdown, we can utilize Jina AI Reader API.
Jina AI give an API key we can use for the first 1M token processed. Once it reaches the limit, we need to top up if we are intended to use the API key.
Afraid not, we can still use their service (for now) even without the API key. Simply do the request with omitting the API key. In this example, we will try to omit the API key.
🚧 Please note the rate limiter is very tight when we are not using the API key. Make sure we are doing graceful requests, otherwise we will get Error 429 – Too many requests
To use it, we only need to perform GET request to their endpoint.
Skip it if you have installed it already
pip install requests
We will try to parse one of my article Exploring Vision Transformers (ViT) with 🤗 Huggingface. You may also change it into any other websites.
import requests
import os
BASE_URL = "https://r.jina.ai"
site = "https://fhrzn.github.io/posts/building-conversational-ai-context-aware-chatbot/"
url = os.path.join(BASE_URL, site)
resp = requests.get(url)
print(resp.text)
And here is the parsed result:
Title: Vision Transformers (ViT) with 🤗 Huggingface | Data Folks Indonesia
URL Source: https://medium.com/data-folks-indonesia/exploring-visual-transformers-vit-with-huggingface-8cdda82920a0
Published Time: 2022-10-14T11:00:46.983Z
Markdown Content:
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (Dosovitskiy et al., 2021)
-----------------------------------------------------------------------------------------------------
[](https://medium.com/@fahrizain?source=post_page-----8cdda82920a0--------------------------------)[](https://medium.com/data-folks-indonesia?source=post_page-----8cdda82920a0--------------------------------)
Lately, I was working on a course project where we asked to review one of the modern DL papers from top latest conferences and make an experimental test with our own dataset. So, here I am thrilled to share with you about my exploration!

Photo by [Alex Litvin](https://unsplash.com/@alexlitvin?utm_source=medium&utm_medium=referral) on [Unsplash](https://unsplash.com/?utm_source=medium&utm_medium=referral)
Background
----------
As self-attention based model like Transformers has successfully become a _standard_ in NLP area, it triggers researchers to adapt attention-based models in Computer Vision too. There were different evidences, such as combine CNN with self-attention and completely replace Convolutions. While this selected paper belongs to the latter aproach.
The application of attention mechanism in images requires each pixel attends to every other pixel, which indeed requires expensive computation. Hence, several techniques have been applied such as self-attention only in local neighborhoods \[1\], using local multihead dot product self-attention blocks to completely replace convolutions \[2\]\[3\]\[4\], postprocessing CNN outputs using self- attention \[5\]\[6\], etc. Although shown promising results, these techniques quite hard to be scaled and requires complex engineering to be implemented efficiently on hardware accelerators.
On the other hand, Transformers model is based on MLP networks, it has more computational efficiency and scalability, making its possible to train big models with over 100B parameters.
Methods
-------
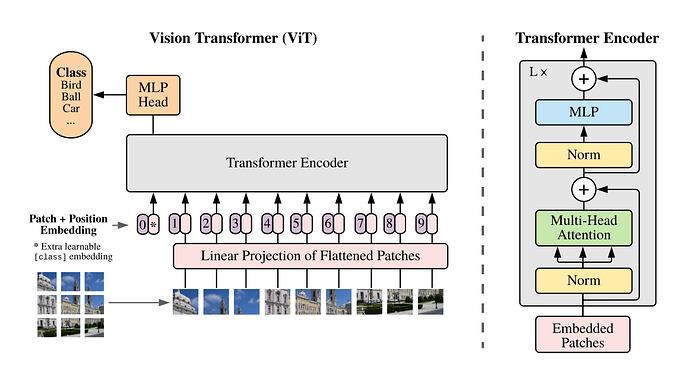
General architecture of ViT. Taken from the original paper (Dosovitskiy et al., 2021)
The original Transformers model treat its input as sequences which very different approach with CNN, hence the inputted images need to be extracted into fixed-size patches and flattened. Similar to BERT \[CLS\] token, the so-called _classification token_ will be added into the beginning of the sequences, which will serve as image representation and later will be fed into classification head. Finally, to retain the positional information of the sequences, positional embedding will be added to each patch.
The authors designed model following the original Transformers as close as possible. The proposed model then called as Vision Transfomers (ViT).
... (We trimmed the output)
Please also pay attention, for some website this technique might not works very well. That probably caused by firewall or cloudflare protection. You may use the proxy to mitigate it.
Also, there are a lot more options provided by Jina AI Reader. You may find it out here https://jina.ai/reader/#apiform.
Conclusion
Maintaining document structures can ensure the quality of LLM response when it getting asked about our documents. Therefore, choosing the right tools is essential. PyMuPDF4LLM ensure the parsed document output is given in markdown format, which is great in maintaining the document structures.
On the other side, Langchain implementation is easy to use. Unfortunately, it lack of ability to preserve document structure. One may extend Langchain API to create a PyMuPDF4LLM integration. So that can take benefit from both sides.
Should you have other opinions or feedbacks, please never hesitate to comment below!
Let’s get Connected 🙌
If you have any inquiries, comments, suggestions, or critics please don’t hesitate to reach me out:
- Mail: affahrizain@gmail.com
- LinkedIn: https://www.linkedin.com/in/fahrizainn/
- GitHub: https://github.com/fhrzn